What Is Data Mining? | Definition & Techniques
Data mining is the process of extracting meaningful information from vast amounts of data. With data mining methods, organisations can discover hidden patterns, relationships, and trends in data, which they can use to solve business problems, make predictions, and increase their profits or efficiency.
The term “data mining” is actually a misnomer because the goal is not to extract the data itself, but rather meaningful information from the data .
What is data mining?
Data mining, also known as knowledge discovery in data (KDD), is a branch of data science that brings together computer software, machine learning (i.e., the process of teaching machines how to learn from data without human intervention), and statistics to extract or mine useful information from massive data sets.
Through our online interactions with companies, government agencies, or educational institutes, we produce a large amount of data. This “big data” consists of data sets so large that it’s not possible for a human to analyse them. Instead, this is done with the assistance of a computer.
Data mining transforms this raw data into practical knowledge that helps organisations answer important questions about their users or consumers. Data mining applications include consumer behaviour analysis, sales forecasting, and fraud detection.
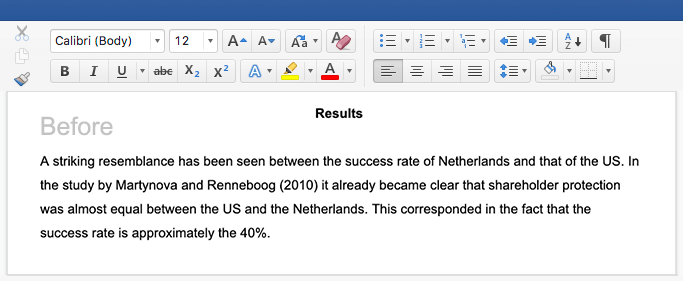
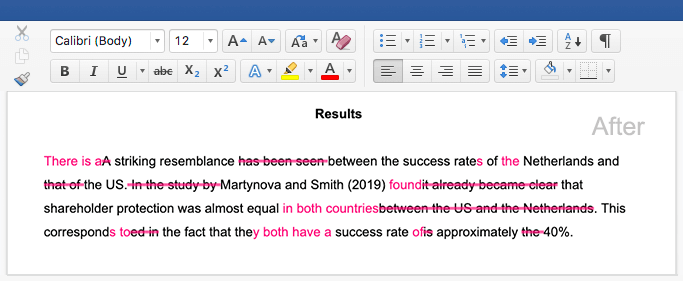
What are different data mining techniques?
Data mining techniques draw from various fields like machine learning (ML) and statistics. Here are a few common data mining techniques:
- Classification is the task of assigning new data to known or predefined categories. For example, sorting a data set consisting of emails as “spam” or “not spam”.
- Clustering is the process of grouping data that share common characteristics into subgroups or clusters. Unlike classification (where groups are predefined), clustering is a discovery technique that helps us identify patterns. This allows businesses to create customer segments based on loyalty, communication preferences, or any other trait that emerges from the data.
- Association rule learning is a technique that looks for relationships between data points. A grocery store chain may use association rule learning to find out which products are frequently bought together and use these insights for promotions.
- Regression is a statistical method used to model the relationship between a dependent variable and one or more independent variables. The goal is to predict the value of the dependent variable based on the values of the independent variables. For example, using historical data about houses with similar characteristics, we might predict the future value of a house.
- Anomaly or outlier detection is the process of identifying unusual data within a data set (i.e., data that doesn’t follow the general pattern). This data may be interesting (e.g., if it signals a spike in the sales of certain products) or may need further investigation (e.g., if it indicates potential instances of fraud).
How does data mining work?
The data mining process involves using statistical methods and machine learning algorithms to identify patterns in data. Thanks to advancements in computer processing power and speed, analysing data is largely automated.
Although there are different ways to describe the data mining process, a widely used model is the Cross-Industry Standard Process for Data Mining (CRISP-DM), which includes the following stages:
Business understanding
In the business understanding stage, we need to identify the problem we intend to solve through data mining (e.g., how to create a more targeted marketing campaign).
Data scientists and other relevant stakeholders need to define the business problem, which will inform the questions that guide the project. Additional research might be necessary to understand the business context. Determining project goals and success criteria is important for collecting the right data and evaluating the project’s outcomes.
Data understanding
Once the business problem is defined, we need to determine the type of data needed and identify relevant sources. In this step, data scientists collect data from various sources, such as transaction records and customer databases.
However, not every data point may be relevant for the project. For example, a company may only be interested in purchases via credit card. The goal here is to ensure that only the necessary data will be included. By the end of the data understanding stage, the data mining team should have selected the subset of data necessary to address the problem.
Data preparation
Data preparation is the most time-consuming stage and involves several actions to get the data ready for further processing and analysis. This may involve excluding duplicates, missing data, or outliers from the data (i.e., data cleansing).
Data from multiple sources may be merged, organised, or adjusted in different ways to prepare for the next phase. At the end of this stage, the data mining team has identified the most relevant variables and prepared the final data set.
By studying these variables, the marketing team can eventually create targeted travel offers that cater to their customers’ specific needs and preferences.
Data modelling
Data modelling is the process of organising and understanding data in a structured way. It helps data mining teams find meaningful patterns and insights in the available data.
Data scientists use different models depending on the type of data they have and the problem they’re trying to solve. For example, they might want to identify which products are often purchased together or detect suspicious transactions in banks. To do this, they may use different techniques.
For example, they may apply classification techniques to categorise labelled data or use clustering techniques to group similar data points together. By iterating through this modelling process, data scientists try to reach the best solution.
They build models that group customers into segments that reflect shared travel interests and characteristics. They find out that their customers mainly consist of three distinct groups: “adventure seekers”, “cultural explorers”, and “family vacationers”.
- Labelled data means that it has been manually annotated with specific information (e.g., emails labelled “spam” or “not spam”). In this case, data scientists can use a supervised machine learning approach, where the model learns from these labelled examples to make predictions on new, unseen data.
- On the other hand, if the data is unlabelled, data scientists can use unsupervised machine learning, which helps them discover patterns and relationships within the data without any predefined labels.
Evaluation
During the evaluation stage, the data mining team begins to assess the model’s effectiveness in answering their initial question. This is a human-driven phase, as the project leader needs to decide if the model answers the original question well or uncovers new and previously unknown patterns.
Unlike the technical assessment in the modelling phase, the evaluation phase involves determining which model best meets the objectives and deciding how to proceed. This involves evaluating the results against success criteria, reviewing the process for any oversights, and summarising findings.
The team may decide, for example, to move on to the next phase or, if the model does not align with the desired objectives, to explore alternative models or revisit the data.
Deployment
The deployment step is about putting the knowledge and insights gathered from the project into practical use.
Depending on the original question or problem, deployment can be something simple like creating a report or a visual presentation, or something more complex like generating a new sales strategy. Deployment involves integrating the results into the organisation’s operations or decision-making process.
Data mining application examples
Here are some real-world examples of data mining:
- Market basket analysis. Retailers use data mining to analyse large data sets and discover consumers’ buying patterns, such as items that are frequently bought together or seasonal trends. They can use this information to better organise their physical stores or websites, predict sales, and promote deals
- Academic research. In the field of literary studies, data mining techniques can be used to analyse texts and understand the emotions expressed by authors or characters. Sentiment analysis (or opinion mining) involves using natural language processing and machine learning algorithms to determine the emotional tone of a text.
- Education. Educational data mining (EDM) aims to improve learning by analysing a variety of educational data, such as students’ interactions with online learning environments or administrative data from schools and universities. This method can help education providers understand what students need and support them better (e.g., through customised lessons or by identifying and engaging with at-risk students before they drop out).
Other interesting articles
If you want to know more about ChatGPT, AI tools, fallacies, and research bias, make sure to check out some of our other articles with explanations and examples.
ChatGPT
Fallacies
Frequently asked questions
Sources for this article
We strongly encourage students to use sources in their work. You can cite our article (APA Style) or take a deep dive into the articles below.
This Scribbr articleNikolopoulou, K. (2023, July 20). What Is Data Mining? | Definition & Techniques. Scribbr. Retrieved 23 July 2026, from https://www.scribbr.co.uk/using-ai-tools/what-is-data-mining/
Yağcı, M. (2022). Educational data mining: prediction of students’ academic performance using machine learning algorithms. Smart Learning Environments, 9(1). https://doi.org/10.1186/s40561-022-00192-z
